

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
 |
Conversational Scene Analysis |
 |
Mania/Depression Assessment |
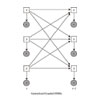 |
The Influence Model |
 |
The Facilitator Room The facilitator room is a computational framework for behavior modification. The goal is to make reliable measurements of the interactions in the room, and then model the effects of actuators on these measurements, and finally using these to facilitate behavior. Joint work with Brian Clarkson, Tanzeem Choudhury. CVPR workshop paper, poster. |
 |
Smart Headphones
|
 |
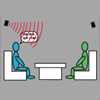
Speech Detection Speech detection, or "endpoint detection" as it is called by the speech community, has not been explored thoroughly due to the standard assumption of a headset microphone. We are interested in detecting speech in an open environment, and do so with a novel algorithm using the harmonic structure of vowels. Joint work with Brian Clarkson. ICASSP paper, poster. |
 |
Pitch Tracking/Prosodic Feature
Estimation While the estimation of pitch and speaking rate have received much attention in the past decades, little of the work has concentrated on robust performance in the far-field case. We are interested in computing these features for a room or wearable setting, where ideal microphone placement is not possible. |
 |
Wearable Phased Arrays This project came from a desire to determine who was speaking when in a wearable setting. Speaker identification techniques fail due to rapid changes; we thus chose to determine the changes in source direction using a wearable phased array. The flexible geometry of the array made it a challenging task. We introduce a dynamic programming algorithm to find when the speaker changes occur. Joint work with Steve Schwartz. ISWC paper, slides. |
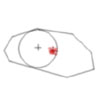 |
Bayes Point Machines Support vector machines (SVM's) are well known for their robustness against generalization error, supposedly due to their maximum margin strategy. The work of Ralf Herbrich showed that a more Bayesian approach to choosing a solution point could yield even better performance. This paper recounts the assumptions made in developing the Bayes Point Machine (BPM) and empirically examines its performance in various data scenarios. Paper, slides. |
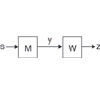 |
Independent Components Analysis |
 |
Using Orthogonal Wavelets
for Multiscale Template Matching Wavelets are well-known as an efficient means of representing audio/visual information. This work shows how orthogonal wavelets can be used for very efficient template matching schemes in which computations from coarser scales can be reused for computations at the finer scales. Examples are shown for entire image matching as well as image mosaicing. Paper. |
 |
Mesh-Based Function Approximation When tracking mesh-based models, it is necessary to smooth the underlying image to allow the computation of gradients. This is typically done with a fixed kernel. However, the mesh gives us insight as to what level of detail to preserve at which location. This paper develops an efficient algorithm for recursive function approximation that is appropriate to the mesh. Joint work with Kentaro Toyama (Microsoft Research). Technical report. |
 |
Maximum A Posteriori Tracking
of Physically-Based 3D Modal Mesh Models There is often little texture to map to each element of a mesh model (as in deformable templates) - sometimes we must be guided only by the probability of belonging to certain classes (lip/skin in our case). We show how this information can be used to very efficiently ascend to a local maximum a posteriori (MAP) solution for modal models. Joint work with Nuria Oliver. Speech Communications journal paper, poster, web page (with videos). |
 |
Training 3D Mesh Models from
Finite Element Priors Naive methods to train a mesh model require tracking all vertex locations in data, which is prohibitive for a detailed mesh. We show how finite element techniques can be used to model the basic properties of the mesh (i.e., stiff and loose regions, etc.), allowing data to be taken at only a few points (17 nodes out of 206) and still effectively train the observed physics of the model. Master's thesis, CVPR workshop paper. |
 |
Optical Flow Regularization
with a 3D Model (applied to Head Tracking) This work shows how 3D models can be used to regularize optical flow. In particular, we use a simple 3D model (an ellipsoid) to approximate the head, and use robust estimation techniques to track head motion in 3D using this model for regularization. The results were exceedingly stable, though drift eventually creeps in due to its purely differential nature. Joint work with Irfan Essa. ICPR paper, CA paper, web page (videos). see also ICCV paper. |
 |
Vision-Steered Audio for Interactive
Environments High-quality audio input and audio imaging in an open environment is a challenge, especially if we do not want to encumber the user with wireless microphones, etc. In this work, we propose a solution using a phased array of microphones for input and an IIR-based cross filter system for output, both steered using information from computer vision (pfinder). Joint work with Michael Casey, Bill Gardner, and Chris Wren. ImageCom paper, AES paper. |
 |
Using Hyperacuity Principles
for Image Enhancement What began as an attempt to justify the use of hyperacuity sensors in scanning technologies resulted in a range of image enhancement techniques for standard scanning mechanisms. We show how hyperacuity principles can be applied to grayscale scans for significant improvements to text/continuous tone appearance/legibility. Joint work with David Biegelsen, Warren Jackson, and David Jared (Xerox PARC). SB Thesis. |