The obvious starting point for the problem of learning to map a sound to a parametric representation is to use the direct inverse modeling strategy. The model learns the inverse mapping by reversing an observed set of inputs and outputs for the instrument, producing a functional mapping between them; instead of a physical action producing a sound, we want the sound to produce the physical action.\
An example of a direct solution to the inverse modeling problem is
classical supervised learning. The learner is explicitly presented
with a set of sound, action-parameter pairs observed
from the physical model, ![]() , and
is trained using an associative learning algorithm capable of
non-linear mappings. Once trained, the learner has the ability to
produce actions from sound intentions, hopefully with good
generalization. This technique is only suitable for modeling data that
is convex in the region of the solution space that we are interested
in, see Figure
, and
is trained using an associative learning algorithm capable of
non-linear mappings. Once trained, the learner has the ability to
produce actions from sound intentions, hopefully with good
generalization. This technique is only suitable for modeling data that
is convex in the region of the solution space that we are interested
in, see Figure  .
.
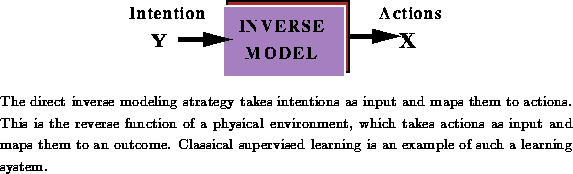
Figure: Direct Inverse Modeling