



Next: Results Up: Synthetic Movies Previous: Video Finger: Software
Next: Results
Up: Synthetic Movies
Previous: Video Finger: Software
The object representation used for Video Finger requires a set of object views, from which the desired task sequences can be assembled. This set of object views may be generated from a computer graphic database or from actual image data obtained using a real subject. Since one of the goals of Video Finger was to incorporate real imagery into the graphic interface, the object descriptions used were constructed from actual image data.
The object view must be separated from the background present in the original object image. There are many ways of implementing this separation; the most common of which is ``blue-screening''. In ``blue-screening'', the object to be filmed is placed in front of a monochromatic matte background. The color of the background is highly saturated, usually blue (hence the name). This allows the background to be separated by post-processing, either by special analog circuitry (a chroma-keyer) or by software. This technique was chosen due to the relatively high resolution segmentation produced, and the ease of implementation. Other techniques considered were not suitable for use with image sequences (laser range camera) or currently provide results with too little resolution (depth-from-focus, depth-from-shading, etc).
The subjects for the prototype Video Finger were asked to stand in
front of a blue background, and perform a number of tasks. In order to allow natural motion, the subjects were recorded using a constantly running video camera and video tape recorder.
The tasks were each repeated at least twice in order to assure that at least one sequence of each task would be acceptable .
The tasks that the subjects were asked to perform varied from subject to subject, but all included a small subset of common tasks, namely twirling around in a chair, standing up and leaving,
entering and sitting down, and falling asleep. Other tasks recorded included walking, reading, and writing.
.
The tasks that the subjects were asked to perform varied from subject to subject, but all included a small subset of common tasks, namely twirling around in a chair, standing up and leaving,
entering and sitting down, and falling asleep. Other tasks recorded included walking, reading, and writing.
The bluescreen consisted of 3/8" plywood, covered with several coats of chroma key blue paint. The subjects were placed approx. 24" in front of the bluescreen, and illuminated by light sources placed inline with (actually about 4" away from) the camera lens. This was done in order to reduce shadowing. The camera used was an Ikegami NTSC camera. It was connected directly to an Ampex 1" videotape recorder used for taping the subjects. Although recording the images in NTSC was suboptimal, the fact that the images were band-limited and decimated in later pre-processing lessened the artifacts.
The recorded images of the subjects were examined in order to determine which frames would be selected to represent the subject. Once selected, the views were decoded from the NTSC signal from the videotape recorder into RGB components using a Faroudja NTSC Decoder. Each component was digitized separately using a Datacube frame buffer mounted in a Sun workstation and transferred to a microVax III for further processing. The resolution of the input images was 768x480. The images were then cropped to 640x480, filtered using a half-band lowpass 13-tap 2D Gaussian filter, and decimated by two in each dimension to provide a 320x240 RGB original image set. This image set was then color quantized to provide the actual images used in the object representation. The color lookup table was generated by applying Heckbert's median cut algorithm[Heckbert82] to a histogram generated from a small number of representative images from the image set.
Although the software supports objects having multiple CLUTs, the color statistics of the object views are relatively constant, allowing most objects to be reasonably encoded using one 256 entry color table. This is not to say that the color statistics of a single view are representative of the entire sequence. Instead, a small number (three or four) of representative views should be sampled in generating the CLUT.
The RGB original image set contained images of the objects against a background. The background region of the image was identified using color segmentation routines developed for this purpose [Watlington88b]. The particular segmentation algorithm used was a region merge algorithm which attempted to form clusters in a two dimensional color space. The color space used for the segmentation was normalized red vs. normalized blue. The output of the segmentation algorithm was an image showing the different regions that had been identified. The background regions (the background was usually identified as three to five separate regions) were then combined to generate a mask image. The mask image was used to set the background region of the color quantized images to a zero pixel value. Zero was the pixel value used to denote transparency.
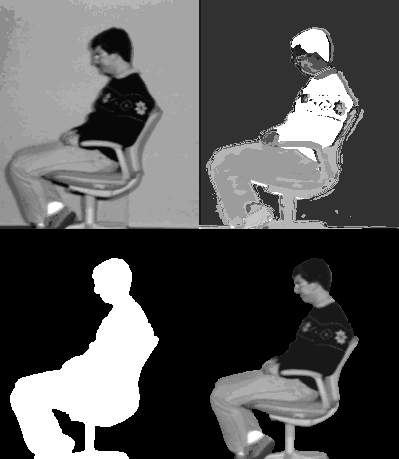
Figure 6.1: Object View at several different stages during processing
The edges of an object are usually a problem with a chroma based image segmentation algorithm, due to object interreflectances, pixel averaging (lens blurring), and shadows. If the object edges are not properly identified, different yet similar views will show different object edges where the edge should be the same. When the images are animated (played), the resulting artifact is an object with edges that appear to wiggle back and forth.
The color image segmentation algorithm used performed relatively well, yet still required two steps of hand editing in producing the mask image. One step was identifying which segmented regions actually belonged to the background, the second was eliminating edge location errors around the object. An example object view during several stages of processing is shown in Fig. 6.1. The images are, in clockwise order from the upper left corner, the original image view, the segmented regions, the mask generated from the segmentation information, and the final object view, separated from the background.
These problems could both be alleviated if additional information about the object view was utilized. If another segmentation algorithm is employed, perhaps utilizing motion over time, or utilizing both range data and luminance data, the first step of hand editing could be eliminated.
The images being processed were often highly similar. Due to the use of a sequence of object images to represent motion, many of the images differed only in the motion of one small section. Errors in segmentation could be reduced by using the information about the object edges and areas of shadow gained by the segmentation of the previous images in the sequence.
The segmentation routine was implemented on the Mac II, as part of PicTool, an image processing utility. PicTool was vital in assembling the image sets, as it allowed the images to be easily viewed, segmented, cropped, and retouched as necessary. Additionally, PicTool provided a programming environment for the quick testing of the view manipulation algorithms used in Video Finger.
The object description may be generated automatically, if additional information is recorded by the camera(s) being used. One possibility is the model building camera developed by V. Michael Bove[Bove89]. This camera records range information derived using depth-from-focus methods as well as luminance information for an image. A sequence of these images, or the images recorded by multiple cameras viewing the same scene are used to generate a three dimensional particle representation of the object [Linhardt88]. This database may be converted into other forms for rendering.
Although the computing requirements of rendering a view directly from the object database generated by the camera are too large to consider doing it on the Mac II, the representation used by Video Finger could easily be generated. Unfortunately, a color version of the camera required is not currently available.