Many of the surveyed systems are characterized by a single programmable core, with an instruction set architecture optimized for the operations typically encountered in either graphics or video processing algorithms. Specialized processing units may be incorporated either into the programmable core, or as co-processors.
Increasingly, general purpose microprocessors are integrating instruction set extensions allowing the processing of multiple small datum packed into a larger word simultaneously [1] [2] [3] in order to gain a slight speed improvement (x2 or x3) in graphics tasks. The minimal costs of these group instruction extensions (increased instruction set complexity, and slightly increased carry propagation delay in the ALUs) compared with the speed improvement when processing typical images justify the extensions. While support for group instructions alone was generally not sufficient for inclusion in this survey, they are a common architectural feature among the video signal processors discussed.
| System | TI | Philips | MicroUnity | Chromatics | Samsung | |
|---|---|---|---|---|---|---|
| 'C6201 | TM1000 | MediaProc | Mpact2 | MSP | Units | |
| Inst issue | 8 | 5 | 1 | 2 | 1 | inst |
| Inst width | 256 | 220 | 32 | 72 | 32 | total bits |
| Inst Cache | 512K | 256K | 256K | 18K | 16K | bits |
| Data Cache | - | 128K | 256K | - | 40K | bits |
| Data Ram | 512K | - | - | - | - | bits |
| Registers | 32x32 | 126x32 | 320x64 | 1Kx72 | 31x32 | bits |
| Data Width | 32 | 32 | 64 | 72 | 32 | bits |
| Func. Units | 8 | 22 | 4 | 4 | 1 | |
| Floating Pt | No | Yes | No | Yes | Yes | |
| Spec. Units | - | 2 | 1 | 2 | 2 |
The TMS320C6201 [4] is the first implementation of a new VLIW architecture, VelociTI [5] [6], just available from TI's DSP group. While it contains no functional units dedicated to video or graphics, it's raw performance makes it interesting. The processing core (currently running at 200 MHz) consists of two each of four types of processing elements: logical (and arithmetic), arithmetic, data addressing, and multiply. All processing elements operate on 32b data except for multiply, which only operates on 16b input values. Up to eight instructions (one per processing element) may be issued in a single cycle. The processing units are grouped into two sets of four, each of which is coupled to a 16x32b register bank. Ten read ports and five write ports are provided per bank. A cross-linked register read port provides direct communication between the two processing clusters, which share a common instruction issue unit.
No data cache is provided (although the architecture allows for one). Instead, directly addressable data RAM is provided on-chip, organized as four interleaved banks of 128 Kbits (8Kx16b) each. Each processing cluster has a separate 32b data path to the data RAM, and two simultaneous 32b accesses may occur if different banks are accessed. A 32b memory interface which can address 64 MBytes of the architecture's 4 GBytes is provided, along with a 16b host interface which is limited to addressing the internal register, data and 512 Kbits of instruction RAM. The memory interface is capable of running at clock rates equal to the processor core, and is designed for synchronous DRAM, synchronous burst SRAM, or async. SRAM. Two channels of DMA are provided on-chip for efficiently moving data around the system.
The instruction set architecture is spartan (esp. in the context of this survey). In the TMS320 tradition, it contains concessions to typical signal processing needs: saturation instead of numeric overflow, a normalize instruction (norm), support for circular addressing, and extended precision (using two 32b registers for a 40b value). There is no support for group instructions, or floating point. The execution of every instruction is conditional. Three bits of each 32b fixed-size opcode indicate a guard register, and a fourth bit indicates whether the execution is conditional upon the guard being equal or not-equal to zero.
The instructions are grouped by the compiler or optimizing assembler into execution groups to be issued in the same cycle. The LSB of each opcode is dedicated to indicating the last instruction in an execution group. One or more of these groups are packed into an eight instruction (256b) fetch group. An execution group may not overlap a fetch group boundary. The instruction RAM (which may be configured as a cache) uses a 256b bus to provide a fetch group to the CPU every cycle.
Unlike the TMS320C6201, the Philips TriMedia TM1000 [7] [8] [9] integrates Media specific co-processors and a VLIW core with extensions for media processing. It was designed to be a PCI based media co-processing system in a PC. Based on the LIFE-1 VLIW architecture developed at Philips Research Labs, Palo Alto, in 1987, it started development as a product in 1994, and the TM1000 (previously named the TM-1) shipped in early 1996. A second generation is now in development.
The VLIW core contains a large number  of functional units, connected to a
128x32b register bank through 15 read ports and 5 write ports. A
listing of the functional units is provided in Table
2. Up to five instructions may be issued in a
single 10 nS cycle. The instruction set is large (197), having been
extended to support the specialized functional units and floating
point. Group instructions are supported, operating on four 8b or two
16b values in a 32b word, as well as packing and unpacking
instructions. Specialized instructions are provided for performing
convolution and vector distance (i.e. motion estimation) calculation.
As in the TMS320C6201, the execution of almost every instruction is
conditional upon a guard register.
of functional units, connected to a
128x32b register bank through 15 read ports and 5 write ports. A
listing of the functional units is provided in Table
2. Up to five instructions may be issued in a
single 10 nS cycle. The instruction set is large (197), having been
extended to support the specialized functional units and floating
point. Group instructions are supported, operating on four 8b or two
16b values in a 32b word, as well as packing and unpacking
instructions. Specialized instructions are provided for performing
convolution and vector distance (i.e. motion estimation) calculation.
As in the TMS320C6201, the execution of almost every instruction is
conditional upon a guard register.
| Unit | Number | Unit | Number |
|---|---|---|---|
| Int. ALU | 5 | Load/Store | 2 |
| DSP ALU | 2 | DSP Mult. | 2 |
| Shifter | 2 | Branch | 3 |
| Int/FP Mult | 2 | FP ALU | 2 |
| FP Compare | 1 | FP Sq.Root | 1 |
| Constant | 5 |
The VLIW core is connected to a 128 Kbit data cache (8-way associative) using two 32-bit buses. A separate 256 Kbit instruction cache (also 8-way associative) uses a 220b bus to provide five instructions per cycle to the CPU. The instruction stream is stored and cached in a compressed format, and decompressed to provide the 220b instructions only upon being fetched. The data and instruction caches share a single 32b main data bus (the Data Highway) with all the co-processors and peripherals on the chip. The Data Highway connects to both a 32b PCI bus interface (master/slave), and a memory interface (32b) to off-chip synchronous DRAM. The architecture address space of 4 GBytes is fully supported throughout the system.
The Image Co-processor is a pipeline of specialized processors designed to perform typical image manipulations (at 50 Mpixels/sec. peak) independently of the VLIW core. It reads its parameters and image data from SDRAM memory using the Data Highway, and writes its output either back to SDRAM or to a destination on the PCI bus. A set of FIFOs (6 x 512b) are provided at the input to the co-processor, feeding a 5-tap polyphase 1D FIR filtering unit. The filtering unit processes a single 8b channel at a time, using multiple passes to perform operations on multiple color channels. A YUV/RGB converter is next, followed by an alpha-blending unit (if used, a separate background image is also input), and an output formatting stage. The Image Co-processor is microprogrammed, allowing it to be reconfigured for different data formats and functionality.
A Variable Length Decoder, designed to decode MPEG and MPEG2 system
bitstreams, is also provided on-chip. Like the Image co-processor, it
contains DMA controllers for reading and writing data from the SDRAM.
Both co-processors synchronize with the VLIW core by interrupting it.
Other peripherals incorporated on-chip are CCIR-601/656 video input and output
(the video output incorporates one last alpha-blended overlay), digital audio
I/O, and two serial interfaces ( 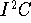 and V.34/ISDN).
and V.34/ISDN).
| System | TI | Philips | MicroUnity | Chromatics | Samsung | |
|---|---|---|---|---|---|---|
| 'C6201 | TM1000 | MediaProc | Mpact2 | MSP | Units | |
| Clock | 200 | 100 | 300 | 120 | 50 | MHz |
| Chip/ICache | 6.4 | 3.2 | 38.4 | 8.6? | 6.4 | Gbits/sec |
| ICache/Proc | 50 | 22.4 | 38.4 | 8.6 | 1.8 | Gbits/sec |
| Proc/Reg | 196 | 64 | 154 | 104 | 154? | Gbits/sec |
| Reg/DCache | 12.8 | 6.4 | 77 | - | 51 | Gbits/sec |
| DCache/Chip | 6.4 | 3.2 | 38.4 | 104 | 6.4 | Gbits/sec |
| Chip/System | 3.2 | 4.2 | 35 | 10.4 | 4.2 | Gbits/sec |
| Reg Size | 1 | 4 | 10 | 73 | 1+ | Kbits |
| DCache Size | 512 | 128 | 256 | - | 40 | Kbits |
The use of a single programmable CPU core to perform ALL operations in a system is a cornerstone of the MicroUnity MediaProcessor architecture. From the perspective of this survey, the interesting architectural features of the MediaProcessor are:
MicroUnity has ceased trying to fabricate its own chips in 0.5 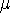 m
BiCMOS (with a 1 GHz clock rate), and is now solely targetting CMOS
implementations [12]. The numbers given in the tables are
for the Chronus CMOS implementation of the MediaProcessor. The specialized
processing element referred to in Table 1 is the unit
supporting ``extended mathematics'': Galois field multiply and polynomial
multiply/divide.
m
BiCMOS (with a 1 GHz clock rate), and is now solely targetting CMOS
implementations [12]. The numbers given in the tables are
for the Chronus CMOS implementation of the MediaProcessor. The specialized
processing element referred to in Table 1 is the unit
supporting ``extended mathematics'': Galois field multiply and polynomial
multiply/divide.
| System | TI | Philips | MicroUnity | Chromatics | Samsung | |
|---|---|---|---|---|---|---|
| 'C6201 | TM1000 | MediaProc | Mpact2 | MSP | Units | |
| Fab. Tech. | CMOS | CMOS | CMOS | CMOS | CMOS | |
| Line Size | 0.25 | 0.35 | 0.6 | 0.35 | 0.5/0.35 | micron |
| Metal Lyrs | 5 | 4 | 3 | 3 | ? | |
| Clock | 200 | 100 | 300 | 120 | 50/100 | MHz |
| Voltage | 2.5 | 3.3 | 3.3 | 3.3 | 3.3 | V |
| Package | BGA | BGA/QFP | BGA | QFP | ? | |
| Pins | 352 | 240 | 441 | 304 | 128/256 | pins |
| Power | 4.2 | 4 | ? | ? | 4 | W |
| Area | 270 (?) | ? | 250(?) | ? | ? | sq. mm. |
| Ext. Mem. | SDRAM & SBSRAM | SDRAM | SDRAM | RDRAM | SDRAM |
Chromatics has been shipping the Mpact1 [13] [14] (several versions) since Sept. '96. They have now announced the second generation in the architecture, Mpact2 [15] [16] which has more off-chip memory bandwidth, new fab. technology w. faster clock rate, larger data RAM with more ports, and the addition of an instruction cache and a specialized processing pipeline for 3D graphics.
| Unit | Input Ports | Output Ports | Floating Point | Description |
|---|---|---|---|---|
| ALU1 | 3 | 2 | Yes | Shift/Align, Juggle |
| ALU2 | 2 | 1 | Yes | Logic, Arith, supports FFT butterfly |
| ALU3 | 6 | 2 | Yes | Logic, Arith, 3-input ops on 144b words |
| ALU4 | 2 | 2 | Yes | Wallace tree for Multiply |
| ALU5 | 1 | 1 | No | Motion Estimation |
| ALU6 | 1 | 1 | No | Graphics Pipeline |
The Mpact2 processor contains a VLIW core capable of issuing one or two instructions packed into a 72b word per cycle. Instead of separate data cache and registers, Mpact2 uses a single 73 Kbit (8Kx72b) bank of RAM with 6 read and 6 write ports. This central multiport memory is accessed through an 11-port crosspoint by the six functional units, a 32b PCI interface, a CCIR601/656 video I/O interface, random peripherals, and two Rambus interfaces. Rambus specifies 9b memory devices (for parity purposes) -- the Mpact architecture uses the ninth bit for additional precision, giving data sizes of 9b, 18b, 36b, and 72b.
The two specialized functional units (see Table 5) are targeted at accelerating 3D graphics and motion estimation (vector distance). The graphics unit is a 35-stage scan conversion pipeline, capable of rendering 50Mpixels/sec. The pipeline performs 18b z-buffered compositing, Gouraud shading, perspective and texture mapping. An 18 Kbit texture memory is provided as part of this unit. The motion estimation unit is capable of computing the vector distance between two 128-element vectors per cycle (8b elements.)
The programming model/instruction set architecture of the Mpact2 is proprietary -- Chromatics develops all firmware (currently providing drivers for accelerating Microsoft products through DirectX.)
The Samsung Media Signal Processor [17] [18] consists of a conventional 32b RISC core (ARM7) coupled with a custom vector processor. The ARM7 instruction set architecture contains explicit support for up to 16 co-processors. Dedicated synchronization signals and test instructions are provided to signal the completion of a co-processor instruction to the ARM core. Both the core and the vector co-processor share a cache subsystem (40 Kbits of data cache and 16 Kbits of instr. cache.) A 64b bus connects the cache subsystem, a 32b PCI bus interface, and an optional memory controller connected to external SDRAM (32b data bus).
Little has been published about the vector processor. It is described
as a SIMD architecture, and from the performance figures cited
it probably contains sixteen 32b processing elements. It supports
group instructions, and like the Chromatics Mpact it supports a 9b
data type, although only internally. The vector processor is supplied
with data through two 256b buses from the shared cache subsytem. A
separate MPEG2 bitstream processor is also provided on-chip.
There are several processors which deserve to be included in the above group, but which for one reason or another (mostly time) weren't described or considered. Four of these, the Mitsubishi D30V [19], the Fujitsu MMA [20], the Sony Video DSP [21] and the C-Cube Video RISC 3, are similar to the processors described above.
A fifth, the Texas Instruments TMS320C80 [22], is a five-way MIMD architecture that has been available for several years but has not seen widespread market acceptance. This is probably due to the difficulty in parallelizing application code for execution on the 'C80. Witness TI's introduction of the 'C6201, which isn't appreciably more powerful, but easily supports the available parallelism through a simple source code recompile.