Revisiting bottlenecks in automated AI research
Simon Williamson has his pelican test for LLMs. I have one for reproducing my old NeurIPS creativity workshop paper on evolving 3D shapes, which I also mused about here.
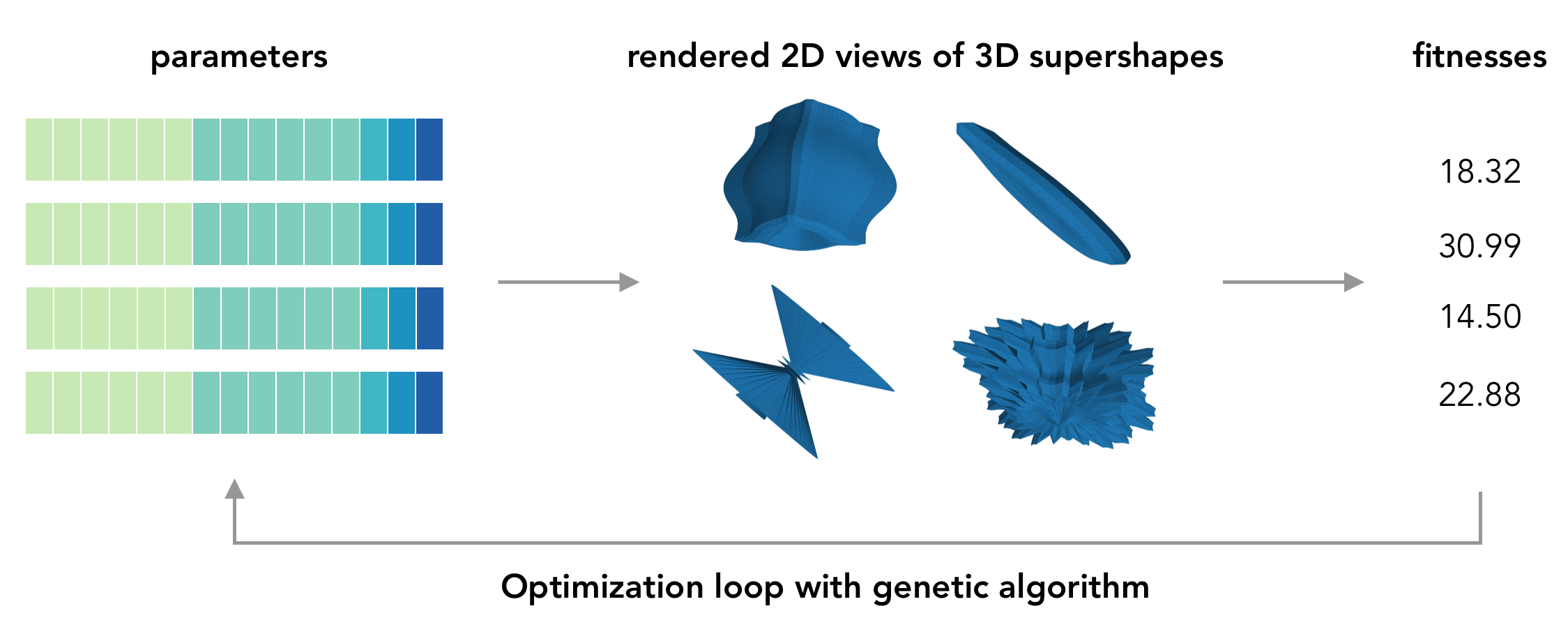
I like this test personally, for a few reasons:
- The original code is short (~500 lines).
- It requires multiple capabilities: coding, agentic tool use, multimodal.
- The most "interesting" part of the paper imo is the overall concept itself.

I first started testing this while developing coding capabilties for PaLM 2. That was a bit ambitious then, and not very successful.
Models today are a lot better. In particular, there have been significant improvements in:
- instruction following: I can now provide a minimal prompt asking to "re-implement this paper", rather than providing detailed, paragraph-level instructions.
- tool use abilities: I can just point to the Arxiv link.
- long-horizon coding abilities: I can let the program run and try to debug itself for sometime in the background, while I do my real work.
However, they still fail for the following reasons:
- Downloading and using CLIP: surprisingly hard (or not, depending on your mental model).
- General coding capabilities, and iterative self-debugging: e.g. rabbit-holing down incorrect theads, or hallucinating/making incorrect assumptions to circumvent a failure.
- Assessing the outputs visually.
- Ideation and taste: this is harder to test, but I haven't yet seen models come up with simple, neat (imo) ideas like this.
Excluding the last point, which may not matter significantly in the grand scheme of auto-research, all these should be solved within the year.
Of course, real auto-research tests a bevy of other capabilities, e.g. performance engineering, truly long-horizon tasks, and continually learning over multiple experiments.