Streams Pattern
(This material is not based on the material in PLoP'94.)
Also Known As
Pipes and Filters, Dataflow
Synopsis
Process a stream of information by feeding it through a network of
independent and reusable processing units.
Context
You want to apply a series of operations to one or more streams of data.
For example, filtering an image, analyzing an oscilloscope signal,
summarizing a movie, or formatting simple text files.
Forces
-
The amount of data is unbounded.
-
Operations may consume unpredictable amounts of time or data
before producing output.
-
Intermediate results may need to be used in multiple places.
Solution
Give data sources and data operators the same interface. Use the Decorator
pattern to construct a dataflow network where operators decorate the
sources of their data.
Each data stream is indexed by time, which may be multidimensional.
Computation is initiated by calling the Get(time_range) method
on a node of the network. If the node is a data source, this instructs it
to return the block of data corresponding to the given time range. If the
node is an operator, this instructs it to fetch data from its source and
return the processed output corresponding to the given time range.
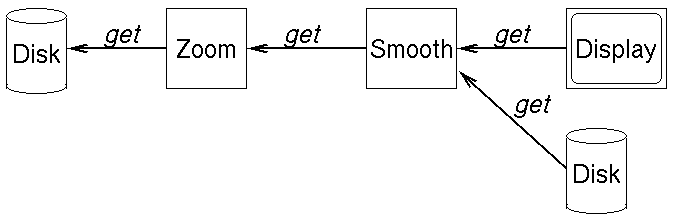
This is the "pull" solution. See below for the "push" solution.
Consequences
-
The network can process an unbounded amount of data, one block at a time.
-
Operators can expand or contract time, thereby processing different amounts
of data for the same request.
-
Multiple streams can be merged by synchronizing on the time index.
-
Time indexing eliminates unnecessary computation. For example, if the
interleaving of two streams is later downsampled by two, only one of the
streams needs to be and will be computed.
-
Intermediate results can be cached to allow efficient fan-out.
-
Nodes are loosely coupled. They are oblivious to the structure of the
network except for their immediate inputs. Nodes can take advantage of
special hardware.
-
Loops in the network are not allowed unless there are delay nodes which
shift time.
Implementation
-
If there is no fan-out, i.e. the network is a chain or collapsing tree,
then time indexing can be avoided. Computation is initiated by
Next(count), to get the next count units of data.
-
Operations can be lazy or eager. A lazy operation does not
compute anything until it is asked for. An eager operation constantly
computes new output, putting it in a buffer, until the buffer space is
exhausted. Then it waits for someone to request the data and empty the
buffer. Eager operations are useful when operations can run in parallel
and their outputs are usually needed.
-
Operators can submit new requests to their source while processing the old
data, providing opportunities for parallelism in the network. Nodes can
reject requests if they are too busy already, thus allowing the parallelism
to automatically adapt to the length of the network.
-
Nodes can cache their output in case it is requested again, e.g. due to
fan-out. Operators can flush their caches at will, but sources may need to
keep data around forever. Caches can be separate nodes.
-
If nodes can mutate, thereby changing the output for a particular time
index, then there must be a way to invalidate caches downstream. A node
which caches its output can use the Observer
pattern to accomplish this while maintaining decoupling.
Some of the optimizations used in the Interpreter pattern are automatic with Streams.
For example, dependencies are explicitly reflected in the structure of the
network. All nodes can run in parallel (though perhaps on different time
slices). Dead values are never computed by lazy nodes since they are never
asked for. Effect caching and partial evaluation can still be done,
however. For example, when an identical block of data is input to a node,
the output will also be identical. Unfortunately, such matches seem rare
in applications.
Alternative solution
A different solution to the Streams problem is sometimes used, where what
comes out of the network is simply determined by what goes in. This "push"
solution is useful for interactive visualization. It is also used in
dataflow processors.
Instead of using Decorators, each node points to the nodes which
follow it in the network. Operators fetch data from their input
queue, process it, and send the result off to the input queues of the nodes
which need it. This approach relies on eager computation and therefore is
not appropriate for some applications, such as accessing a database. For
general-purpose programming, though, it is preferred since it allows loops
and procedure calls, i.e. using the same sub-network in multiple places.
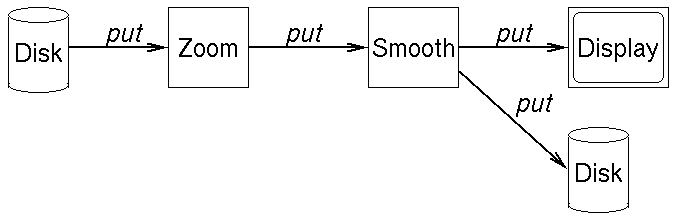
Known Uses
-
The Unix shell uses eager parallel processes to evaluate a pipeline
command. There is no fan-out so no time indexing is used. The interface
between processes is exceedingly simple: characters go from
stdin to stdout. Processes are so independent
that they can be written in any programming language. Unix manages the
buffers and suspends processes automatically, making the buffering
transparent. So it is equally fair to call this a push or a pull
design.
-
MIT Scheme includes a special kind of list, called a stream, which is only
evaluated on demand. Functions on streams can be composed to form a
dataflow network as in the Streams pattern. There are lots of examples in
Structure and Interpretation of Computer Programs.
Haskell
extends this idea by evaluating all expressions on demand.
-
SGI's
ImageVision library uses the Streams pattern for processing images. It
uses 3-D indexing (two space dimensions plus time for movies). Operations
are lazy and cached.
-
LabView,
Opcode's Max, IRIS Explorer, and Khoros use the
Streams pattern to represent arbitrary dataflow programs for visualization
and multimedia. They use the alternative solution based on push rather
than pull.
-
Dataflow processors, such as MIT's Monsoon, use a parallel
machine language based on the Streams pattern (push variant). The MIT
course on Dataflow
Languages and Architectures discusses these in detail.
-
Item
Streams uses the Streams pattern to compose musical patterns.
Thomas Minka
Last modified: Fri Sep 02 17:23:11 GMT 2005