Distributed Objects case study
Distributed objects can roam freely across the network, between RAM and
disk drives, preserving their identities and functionality. They provide
an easy route to making object-oriented programs distributed. However,
keep in mind that the developer must still decide how objects should be
distributed, which can have a significant impact on system performance.
The developer must also provide synchronization, since distributed systems
are inherently parallel.
Distributed objects are also a key enabling technology for component
software. Naturally, just because your objects are distributed doesn't
mean that they can be combined with someone else's objects to form an
application. Component software requires a library on top, for linking,
embedding, data transfer, and automation. We will discuss such libraries,
e.g. OpenDoc and ActiveX, in the next case study.
Distributed Shared Memory
Distributed shared memory (DSM) is making another machine's virtual memory
look like more of your virtual memory. DSM is the core idea behind
distributed objects, as well as distributed file systems and cache-coherent
multiprocessors. Many of the issues in implementing distributed systems
are also DSM issues.
DSM provides three key services:
- Persistent, distributed naming
-
Conventional languages only support naming in the form of pointers, which only
make sense in the context of a particular process on a particular machine.
DSM lets a name apply to any data throughout the network, even if the data
migrates. You can think of a persistent name as being a really big pointer
(e.g. 128 bits) that never goes out of date until the object, not
a particular process or machine, dies. The Domain Name System (DNS)
is an example implementation.
- Global invocation
-
Conventional languages only allow invoking an object which is in the same
process. Object-based DSM lets you call methods on any object that you
can name. It is the object-oriented version of Remote Procedure Call (RPC).
- Migration
-
Conventional languages only support movement through copying. This doesn't
work with a bank account, which must have exactly one instantiation at any
time. Imagine what would happen if I simply copied my account to another
machine. The withdrawals I make on one machine would be invisible to the
other machine, so suddenly I've doubled my money! Migration allows
my account to move from machine to machine, based on who wants to use it,
while remaining consistent.
What follows is a brief tutorial on DSM. You can learn more about DSM from Computer
Architecture: A Quantitative Approach (2nd ed) or from the many MIT
courses on computer architecture and systems. For pioneering research
papers, see the Orca home page.
Design issues
There are four orthogonal issues in designing a DSM.
The first issue in DSM is the unit of distribution.
Here are three possibilities:
- Page-based DSM
-
Distribute the virtual memory pages.
A disadvantage is that objects may span page boundaries, or may happen to
live together a single page, causing false sharing (two processors
needing different parts of a page).
- Shared variable DSM
-
Distribute individual memory locations. Essentially page-based consistency
at a finer granularity. False sharing is nonexistent. Advantageous when
the number of shared locations is small, because of the overhead for each
location.
- Object-based DSM
-
Distribute object state. By using medium-sized units
that are meaningful to the application, it simultaneously enjoys low
overhead and low false sharing.
Object-based distribution is the basis of distributed objects.
Compared to the others, it has the additional complications of:
- Embedded links. Do embedded object references have to be global?
If not, what happens when an object moves?
- Indirection overhead. Private object state can only be accessed
through methods.
- Inheritance. A type lattice may need to be traversed in order to
find the correct method implementation.
- Unknown method behavior. Operations on objects, unlike pages or
variables, can have arbitrary side-effects, like reading and writing other
parts of the memory, and they can have arbitrary duration.
For objects, a "read" means calling a method which does not change the
object state. A read can, however, change another object's state, which is
considered a write to that other object.
The second issue in DSM is migration, which can be automatic or
manual. Automatic migration seeks to place data at the weighted center of
its users, in order to minimize network traffic. One technique is to
periodically look at the origins of the last k requests and move
to their center. This should not happen too often or thrashing may occur.
Manual migration is when the application controls data movement. This is
needed for things like autonomous agents or archival.
The third issue in DSM is replication, which can be static or
dynamic. Static replication uses a fixed mapping for the replicas of an
object. It is usually used to eliminate network bottlenecks and for
fault-tolerance. Dynamic replication uses replicas to reduce network
traffic. For example, read replication uses local caching for
reads. However, writes become more expensive, in order to keep the caches
consistent. All writes must go to the primary copy, whose location may or
may not change, depending on whether the DSM uses migration. As usual with
the Observer pattern, write notification can
use an invalidate or update protocol. Also, someone must
keep track of the replicas.
The fourth issue is the memory consistency model. So far, we have
tacitly assumed sequential consistency, where all reads and writes
appear as though they were executed on a single memory location by a single
processor, i.e. they are totally ordered. However, this requirement is not
necessary for distributed applications which are well-behaved, i.e. have no
race conditions. Thus there are several so-called relaxed consistency
models, which work fine for well-behaved programs and allow more aggressive
DSM algorithms, e.g. caching writes. See the above references more
details.
Implementation
The simplest kind of DSM is the central server algorithm: objects
don't move after creation and are not cached by clients. All requests to a
remotely-created object entail an RPC. JavaBeans uses
this algorithm, probably because it is significantly simpler than ones
based on migration or replication. As usual, implementation is simple
until it has to run fast.
For scalable, high-performance DSM with migration and/or replication, the
most common implementation is to use a directory. For each memory
unit, the directory stores
- who "owns" the unit, i.e. has the primary copy
- who has copies of the unit
This technique scales because the directory can itself be distributed,
migratory, and replicated. This is analogous to virtual memories which
page their own page tables.
DSM applications must normally use an extended naming scheme for all data
pointers. However, if the DSM is object-based, the Proxy pattern can be used to avoid this. All
objects appear local; the truly remote ones have Proxies which forward
requests to them. Objects can easily migrate via the hot swap
technique. When they migrate, embedded references become Proxies.
Identical Proxies in the same address space can be merged.
Object-Oriented Database
A major disadvantage of conventional DSM is that it is based on virtual
memory, which is a proprietary format of the operating system. As soon as
you take an object out of virtual memory, e.g. to store it, it leaves the
global namespace.
Object-oriented databases extend DSM to include disk archives. In other
words, migration is not only from process to process but also to disk.
Persistent names still apply when an object has migrated to disk.
(Embedded references become persistent names when an object is stored.)
Invocation also works: the database will "resurrect" a receiver in storage,
invoke it, then save it again.
The Proxy pattern can still be used to make
remote or archived objects appear local. Proxies can selectively read in
parts of the object, rather than resurrecting the whole thing at once.
Object Request Broker
The last section was motivated by saying that conventional DSM is too
limited in scope. However, databases have simply widened the scope
slightly to include disk archives. They still require objects to be in a
proprietary format, which doesn't work for existing applications.
An Object Request Broker (ORB) is a DSM or database which is designed to be
open and interoperable. It can use data from legacy code or from other
ORBs. The openness is based on either a description language or a binary
standard. CORBA and COM are ORBs. CORBA takes the description language
approach while COM uses a binary standard. Neither provides all of the
services of a database, so they primarily function as shared memories.
If interoperability is based on a binary standard, the Adaptor pattern can be used to introduce objects
into the namespace. Otherwise, the object must be describable in the ORB's
description language. This allows the ORB to automatically create an
Adaptor.
A remote method call therefore looks like this:
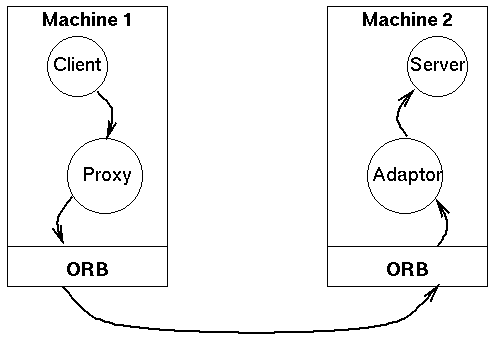
For further reading, see the Broker pattern, available here,
or any of the numerous sites on CORBA and COM.
Broker Example
This example demonstrates an ORB with read replication, notification via
update, and no migration. The event timeline is:
-
Server creates Object.
-
Server registers Object with the ORB.
ORB assigns a fresh, persistent name.
-
Client receives a Proxy containing Object's name. For example, as the
return value of a method call on another object.
While physically different from Object, Proxy does not
have a persistent identity of its own.
-
Client sends a read message to Proxy.
-
Proxy is lightweight; it contains no data at first. Therefore, Proxy
contacts ORB, asking for Object's state.
-
ORB looks up Object's address and connects via Adaptor.
ORB serializes Object's state and sends back to Proxy.
Embedded objects are sent as additional lightweight Proxies.
-
ORB records Proxy as a replica of Object.
-
Proxy receives the state of Object, then executes the read request.
This may invoke other objects.
-
Client sends a write message to Proxy.
-
All writes must go to the primary copy. Therefore, Proxy gives the request
to ORB.
-
ORB gives the request to Object.
-
Object notifies ORB of a change in its state.
-
ORB broadcasts the new state of Object to all replicas, including Proxy.
-
Proxy receives the new state and is now finished with the write operation.
-
Client sends a destroy message to Proxy.
-
Proxy unsubscribes as a replica of Object and dies.
-
Server sends a destroy message to Object.
-
Object removes its name from the ORB and dies.
Description Languages
The example illustrates how much the ORB must know about your object.
It must be able to create a proxy, create an adaptor, serialize the object,
and anticipate side-effects. Where does it get this information?
Here are four possibilities:
- Do it yourself
-
Each class provides its own proxy, adaptor, serialization routine, and
list of "reader" and "writer" methods. This provides maximum control.
Unfortunately, it is a lot of work for old and new classes and requires
exposing some of the internal operations of the ORB.
- Use built-ins
-
Implement your classes in terms of a fixed set of built-in classes. For
example, Python, Smalltalk, and other dynamically-typed languages work this
way. All of the method calls are standard and can be efficiently
implemented in advance by the ORB. Unfortunately, this entails using a
particular programming language, which is one of the things ORBs are intended
to avoid.
- Deduce it
-
Deduce the information from the normal class declaration and
implementation. This would work except for the fact that most
programming languages were designed without distribution in mind. They
often leave key details out of class declarations that are only visible in
the details of the implementation. You could switch to a better language,
but that again is a closed solution.
- Describe it
-
Describe the object in a special language, and generate code from the
description. This is good for foreign objects since they just need to be
described, not rewritten. You need to describe the object's interface,
state, and side-effects. (You must use another language for the
implementation, but a simple conversion tool can give you a head start with
the declarations.)
These can be used simultaneously. For example, a class could have its
proxy and adaptor generated from a description language, have its
side-effects deduced automatically from the implementation, and provide its
own serialization routine.
Both CORBA and COM use Do-it-yourself serialization and Describe-it
for generating proxies and adaptors. As in RPC, the special language is
called the Interface Description Language (IDL). Since objects in
every language must be mapped onto it, IDL tends to have lots of modern
features like class types, triggers, and multiple interfaces. IDLs may
become the new playing field for type research, especially since you don't
have the overhead of an entire language.
Thomas Minka
Last modified: Fri Sep 02 17:23:40 GMT 2005