| index | back | 4.1. System description - 4.2. System architecture - 4.3. User intention | next |
| 4.4. Avatar behavior - 4.5. Sample interaction - 4.6. Implementation - 4.7. Portability |
Paul is standing by himself on the sidewalk, looking about. Susan walks by on the other side of the street, mutual glances are exchanged as they sight each other, and Paul tosses his head smiling and calls "Susan!" Susan lowers her head smiling while replying "Paul!" emphasized by raised eyebrows. Susan straightens a fold in her jacket as she glances to the side, and approaches Paul across the street. She looks back at Paul when she steps up to him, meeting his gaze, smiling broadly again. Paul tilts his head slightly, opening a palm towards Susan and says "Susan, how are you?" Susan’s face lights up as she exclaims "Paul! Great to see you!"
BodyChat is a system prototype that demonstrates the automation of communicative behaviors in avatars. Currently BodyChat only implements appropriate behavior for conversations involving no more than two users at a time (see section 5.3). However, this is an actual Distributed Virtual Environment that allows multiple users to share the space, potentially creating a number of conversations running in parallel.
The system consists of a Client program and a Server program. Each Client is responsible for rendering a single user’s view into the DVE (see Appendix A). When a Client is run, the user is asked for the host name of a Server. All users connected to the same Server will be able to see each other’s avatars as a 3D model representing the upper body of a cartoon-like humanoid character. Users can navigate their avatar around using the cursor keys, give command parameters to their avatar with the mouse and interact textually with other users through a two-way chat window. A sentence entered into the chat window will also be displayed word by word above the user’s avatar, allowing the avatar to synchronize facial expression with the words spoken. A camera angle can be chosen to be from a first person perspective (from the eyes of the avatar), from a point just behind the avatar’s shoulder or from a distance, encapsulating all participating users.
The novel approach to avatar design presented here, treats the avatar somewhat as an autonomous agent acting on its own accord in a world inhabited by other similar avatars. However the autonomy is limited to animating a range of communicative expressions of the face, leaving the user in direct control of movement and speech content. The avatar continuously tries to show appropriate behavior based on the current situation and modified by the user’s intentions, described as a set of parameters toggled by the user. One can think of this as control at a higher level than in current avatar based systems. This approach starts to addresses the following problems:
Avatar creation and distribution
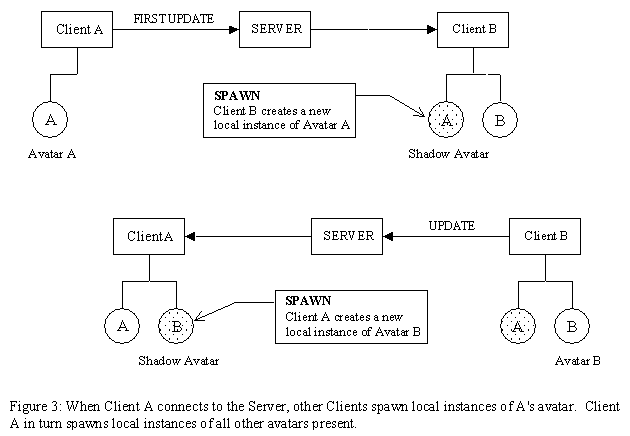
The Server acts as a simple router between the Clients. When a message is sent to the Server, it gets routed to all other connected Clients. The Server gives each Client a unique ID number when they connect. If a Client receives a message from another Client it has not heard from before, it will assume this is a new user, and will spawn a new avatar representing that user. It then sends an update message of its own, to elicit the same creation procedure in the new Client (see Figure 3). The term Shadow Avatar is used here to refer to the avatars in a Client that represent other users, in contrast with the one avatar that represents the user of that particular Client (a users can elect to see their own representation by selecting the appropriate camera angle).
As stated earlier, the avatar can be thought of as a partially autonomous entity. This entity will live parallel lives in different Clients. The avatar’s automated facial expression and gaze will depend on (a) the user’s current intentions, as indicated by parameters set by the user, (b) the current state and location of other avatars, (c) its own previous state and (d) some random tuning to create diversity. All user direction of an avatar is shared with all Clients, including the setting of control parameters. This ensures that all instances of an avatar are behaving similarly, although network lag and the produced randomness factor may vary the details.
A user’s Client distributes three types of update messages, plus a closing message. These messages act as a remote control for the corresponding avatar instances at other Clients. The messages are listed in Table 1.
| Message | Description |
| Motion | Changes in position and orientation caused by the user’s manipulation of cursor keys |
| Chat | Strings typed by the user as the content of a conversation |
| Settings | Control Parameters that describe the user’s intentions |
Table 1: Avatar update messages broadcast from a user’s Client to all connected Clients
Sending a few discrete control settings and then fleshing out the behavior locally in each client instead of having a master instance of the avatar broadcast its behavior to all of its other instances for them to replicate, saves a lot of network traffic and lends itself well to scaling (see Figure 4). With regard to lag times on a network, it is also important to note that each instance is responsible for bringing together the different modalities and producing output that is synchronized within each Client.
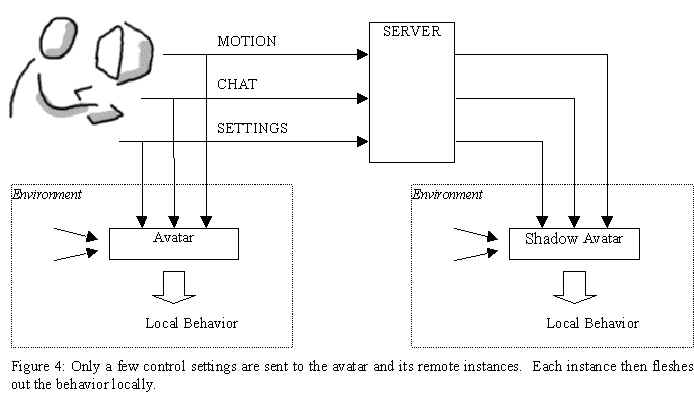
The avatar’s communicative behavior reflects its user’s current intentions. The user’s intentions are described as a set of control parameters that are sent from the user’s Client to all connected Clients, where they are used to produce the appropriate behavior in the user’s Shadow avatars. BodyChat implements three control parameters as described in Table 2.
| Parameter | Type | Description |
| Potential Conversational Partner | Avatar ID | A person the user wants to chat with |
| Availability | Boolean | Shows if the user is available for chatting |
| Breaking Away | Boolean | Shows if the user wants to stop chatting |
Table 2: Control Parameters that reflect the user’s intention
The Potential Conversational Partner indicates whom the user is interested in having a conversation with. The user chooses a Potential Conversational Partner by clicking on another avatar visible in the view window. This animates a visual cue to the chosen Avatar that in turn reacts according to that user’s Availability.
Availability indicates whether the user wants to welcome other people that show interest in having a conversation. This has effect on the initial exchange of glances and whether salutations are performed that confirm the newcomer as a conversational partner. Changing Availability has no effects on a conversation that is already taking place. The user switches Availability ON or OFF through a toggle switch on the control panel (see Appendix A).
During a conversation, a user can indicate willingness to Break Away. The user informs the system of his or her intention to Break Away by placing a special symbol (a forward slash) into a chat string. This is elicits the appropriate diverted gaze, giving the partner a visual cue along with the words spoken. For example, when ready to leave Paul types "/well, I have to go back to work". The partner will then see Paul’s avatar glance around while displaying the words (without the slash). If the partner replies with a Break Away sentence, the conversation is broken with a mutual farewell. If the partner replies with a normal sentence, the Break Away is cancelled and the conversation continues. Only when both partners produce subsequent Break Away sentences, is the conversation broken (Kendon 1990, Schegloff and Sacks 1973).
One of the primary functions of avatars is to indicate a particular user’s presence in the virtual environment and pinpoint his or her location. In BodyChat a new avatar is dynamically created in the environment when the user logs on and removed when a user logs off. For moving around, the system directly translates each press of the forward/backward arrows on the keyboard to a forward/backward shift of the avatar by a fixed increment. Press of the left/right keys is translated to a left/right rotation of the avatar body by a fixed increment. When using either a first person perspective camera or a shoulder view, the viewpoint is moved along with the avatar. The shadow avatars precisely replicate the movement of the primary avatar.
Breathing and eye blinks are automated by the avatar throughout the session, without the user’s intervention. Breathing is shown as the raising of the shoulders and chest. Blinking fully covers the eyes for a brief moment. Some randomness is introduced to prevent mechanical synchrony. The shadow avatars execute this behavior independently from the primary avatar.
When discussing the communicative signals, it is essential to make clear the distinction between the Conversational Phenomena on one hand and the Communicative Behaviors on the other. Conversational Phenomena describe an internal state of the user (or avatar), referring to various conversational events. For example, a Salutation is a Conversational Phenomenon. Each Phenomenon then has associated with it a set of Communicative Behaviors, revealing the state to other people. For example, the Salutation phenomenon is associated with the Looking, Head Tossing, Waving and Smiling Behaviors.
The avatars in BodyChat react to an event by selecting the appropriate Conversational Phenomenon that describes the new state, initiating the execution of associated Communicative Behaviors. Essentially the avatar’s behavior control consists of four tiers, where the flow of execution is from top to bottom (see Figure 5).
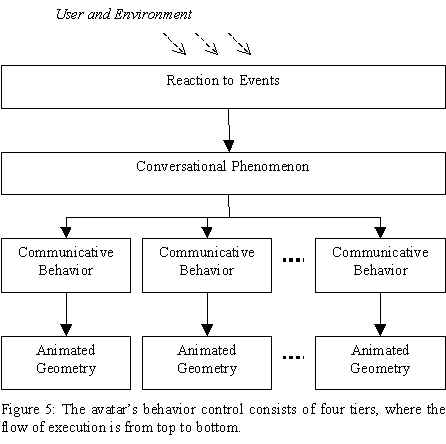
The Reaction to Events tier defines the entry point for behavioral control. This tier is implemented as a set of functions that get called by the Client when messages arrive over the network or by the avatar’s "vision" as the environment gets updated. These functions are listed in Table 3.
This tier is the heart of the avatar automation, since this is where it is decided how to react in a given situation. The reaction involves picking a Conversational Phenomenon that describes the new state of the avatar. This pick has to be appropriate for the situation and reflect, as closely as possible, the user’s current intentions. The selection rules are presented in Appendix B.
| Function | Event |
| ReactToOwnMovement | User moves the avatar |
| ReactToMovement | The conversational partner moves |
| ReactToApproach | An avatar comes within reaction range |
| ReactToCloseApproach | An avatar comes within conversational range |
| ReactToOwnInitiative | User shows interest in having a conversation |
| ReactToInitiative | An avatar shows interest in having a conversation |
| ReactToBreakAway | The conversational partner wants to end a conversation |
| ReactToSpeech | An avatar spoke |
| Say (utterance start) | User transmits a new utterance |
| Say (each word) | When each word is displayed by the user’s avatar |
| Say (utterance end) | When all words of the utterance have been displayed |
Table 3: The Behavior Control functions that implement the Reaction to Events
The Conversational Phenomena tier implements the mapping from a state selected by the Event Reaction, to a set of visual behaviors. This mapping is based on the literature presented in section 3.1 and is described in Table 4.
| Conversational Phenomena | Communicative Behavior |
|
|
| Reacting | ShortGlance |
| ShowWillingnessToChat | SustainedGlance, Smile |
| DistanceSalutation | Looking, HeadToss/Nod, RaiseEyebrows, Wave, Smile |
| CloseSalutation | Looking, HeadNod, Embrace or OpenPalms, Smile |
|
|
| Planning | GlanceAway, LowerEyebrows |
| Emphasize | Looking, HeadNod, RaiseEyebrows |
| RequestFeedback | Looking, RaiseEyebrows |
| GiveFeedback | Looking, HeadNod |
| AccompanyWord | Various (see Appendix C) |
| GiveFloor | Looking, RaiseEyebrows |
| BreakAway | GlanceAround |
|
|
| Farewell | Looking, HeadNod, Wave |
Table 4: The mapping from Conversational Phenomena to visible Behaviors
Finally, each Communicative Behavior starts an animation engine that manipulates the corresponding avatar geometry in order change the visual appearance. In the current version of BodyChat, merging is not performed when different behaviors attempt to control the same degree of freedom. The behavior that comes in last takes control of that degree.
This section describes a typical session in BodyChat, illustrated with images showing the various expressions of the avatars. The images are all presented as sequences of snapshots that reflect change over time. First is a failed attempt to initiate a conversation, followed by a successful attempt, a short exchange and a farewell.
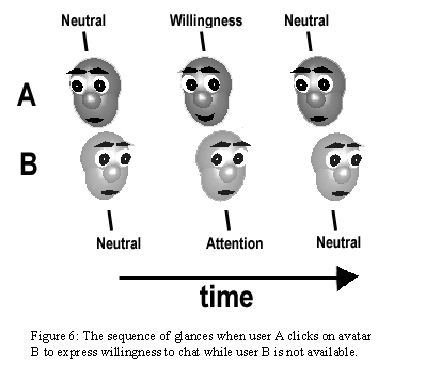
User A is walking around, seeking out someone interested in chatting. After awhile A spots a lone figure that is apparently not occupied. A clicks on the other avatar, expressing Willingness To Chat (see 4.3). The other Avatar reacts with a brief glance without a change in expression. This lack of sustained attention signals to A that the other user is not Available (see 4.3). The automated sequence of glances is shown on figure 6.
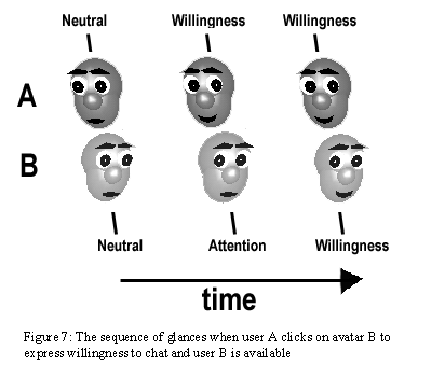
User A continues to walk about looking for a person to chat with. Soon A notices another lone figure and decides to repeat the attempt. This time around the expression received is an inviting one, indicating that the other user is Available. The automated sequence of glances can be seen in figure 7.
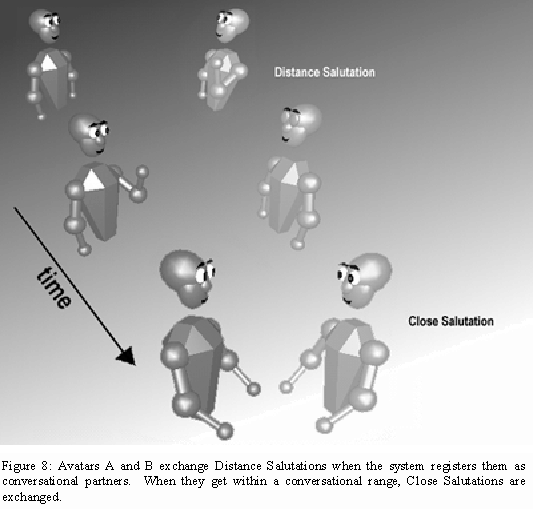
Immediately after this expression of mutual openness, both avatars automatically exchange Distance Salutations to confirm that the system now considers A and B to be conversational partners. Close Salutations are automatically exchanged as A comes within B’s conversational range. Figure 8 shows the sequence of salutations.

So far the exchange between A and B has been non-verbal. When they start chatting, each sentence is broken down into words that get displayed one by one above the head of their avatar. As each word is displayed, the avatar tries to accompany it with an appropriate expression (See Appendix C). An example of an animated utterance can be seen in figure 9.
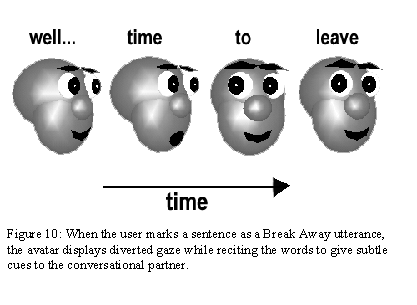
Finally, after A and B have been chatting for awhile, A produces a Break Away utterance by placing a forward slash at the beginning of a sentence (see 4.3). This makes A’s avatar divert its gaze while reciting the words as shown in figure 10. User B notices this behavior and decides to respond similarly, to end the conversation. The avatars of A and B automatically wave farewell and break their eye contact.
BodyChat was written in C++ on an Intel Pentium Pro running Microsoft Windows NT 4.0. Coding and compilation was performed in the Microsoft Visual Studio integrated development environment using Open Inventor graphics libraries from TGS.
Keeping graphics performance adequate imposed limits on model complexity. Texture maps were avoided since they slowed down performance considerably.
Interface classes were built on the MFC Application Framework, conforming to the document-view approach. The document class contains the state of the client and takes care of communicating with the server. The document also holds a pointer to an Open Inventor scene graph representing the virtual environment and maintains a list of all avatars currently active. Three views on the document are vertically laid out in a splitter window. The largest is the World View that contains an Open Inventor scene viewer for displaying the document’s scene graph and a control panel for the user to select the avatar’s control parameters. The smaller views are for displaying incoming messages from other users and composing an outgoing message. An avatar is defined and implemented as a separate class.
Originally the idea was to build the behavior demonstration on top of an existing Distributed Virtual Environment, in stead of implementing a system from scratch. A lot of effort went into researching available options and finding a suitable platform. It seemed viable to implement the avatar geometry in VRML 2.0 and the behaviors in Java and then use a VRML/Java compatible browser to view the result. However, that approach was abandoned for a couple of reasons. First, current implementations of the interface between VRML and Java are still not robust enough to warrant reliable execution of complex scene graph manipulation. This may stem from the fact that the VRML 2.0 standard emerged a less than a year ago and browsers have not implemented a full compliance yet. Secondly, most browsers that already have multi-user support implement avatars as a hard-coded proprietary feature of the user interface, rather than a part of an open architecture suitable for expansion. Since this thesis work was not concerned about standardization or reverse engineering of current systems, it was decided to opt for flexibility by using C++ and Open Inventor.
Although the VRML/Java approach was abandoned for current demonstration purposes, it should by no means be discarded as an option, especially when browsers become more robust. In fact, BodyChat introduces an architecture that lends itself well to the separation of animated geometry (i.e. VRML 2.0) and behavior control (i.e. Java). The VRML model would then implement the set of basic communicative behaviors, such as Smile, Nod, and RaiseEyebrows and the Java module would take care of communicating with the user, environment and other clients to choose an appropriate state for the avatar.