While a resource manager is capable of ``stand-alone'' operation, it is designed to operate in conjuction with identical resource managers running on other processing nodes in a distributed system. While all processing nodes in a locale are typically connected into a single system shared by all users (allowing maximum peak computational resources usage), support is provided for easily separating a subset of processing nodes into a separate system.
A means of identity verification, ensuring that machines entering a system (or separating a subset) are indeed trusted members of the system, will eventually be part of the initialization process. This is required to maintain the protection provided by the tag system.
The distributed system is organized logically
 as a tree with multiple processing nodes at
the top (level 0). At each level in the tree below the top, a node
recognizes a primary node in the level above it, an
alternate in the level above it to be used in case of primary
failure, peer nodes (sharing the same primary node) at the same level,
and nodes for which it is the primary. No one processing node in a
system is crucial to the operation of the system.
as a tree with multiple processing nodes at
the top (level 0). At each level in the tree below the top, a node
recognizes a primary node in the level above it, an
alternate in the level above it to be used in case of primary
failure, peer nodes (sharing the same primary node) at the same level,
and nodes for which it is the primary. No one processing node in a
system is crucial to the operation of the system.
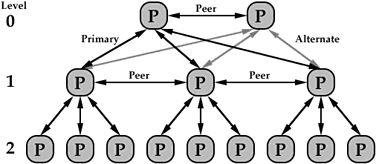
Logical Hierarchy of Processors in a System
When the evaluation of a graph of one or more task tokens and streams is requested, the evaluation is performed locally (if possible). As opportunities for data and control parallelism become apparent, the tasks will be assigned to additional remote processing nodes. This assignment of tasks to processing resources is not done in a single step. Rather, the assignment is done hierachically. When a task is to be applied to a stream, and the stream and task parameters indicate that it may be ``split'' to provide parallelism, the task is subdivided and dispatched to processors in the next level of the hierarchy. Upon evaluation, these processors may further subdivide the task and dispatch it to even lower levels.
This has two effects:
In performing the initial task subdivision and assignment at the top level of the logical organization, the remote computational resources are modeled as aggregates. When a finer subdivision is performed in the next level it utilizes a more local (and hopefully more accurate) model of available resources. This attempt to ameliorate the effects of errors in the model of remote computational resources.
Once the ``scheduling'', or mapping onto currently available processor resources is performed, the dataflow graph is executed relatively independently of the originating node. The ``serial'' portions of the application will be scheduled for execution on the primary node, but may migrate to alternates (which become primaries and name new alternates) if needed (e.g. due to overloading or failure of the originating node.)
In a similar manner, the data storage for streams and other distributed data objects is allocated and searched in a hierarchical manner. When a particular context of a stream is referenced by the parameters of a task, and the stream isn't known to the processor node, it queries other nodes in the system for information about the stream. Cues about which remote nodes might have a particular context of the stream is part of the stream data structure replicated on each node in a system accessing that stream.