There are two basic methods of evaluating the dependency graph which describes a program: demand driven (or call-by-need) and data driven (call-by-value). A data-driven approach performs a computation as soon as the required input values are available. While this ensures that a computation is performed as soon as possible, it may result in unneeded computations being performed. Visualize, for example, a program that only wants to output a small region of interest of a large input dataset.
While a demand-driven approach prevents unnecessary computations from being performed, a demand for application output sees the complete computational latency of the application before the requested data is available. The demand driven evaluation, or eduction [AFJW95], of a dependency graph is described by two rules :
Eduction is simply tagged, demand-driven dynamic dataflow, where the tag includes the multidimensional context of the data.
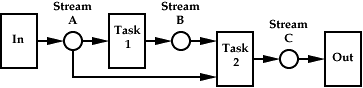
A Simple Program Graph
Exactly determining the appropriate input stream fragment for producing a given output fragment is only possible given a constant rate (deterministic) process. If constant rate, the information used by the resource manager for stream splitting and pipelining (the extent, offset, dimension, and step of stream inputs and outputs to a task), in conjuction with a task history (which establishes the absolute relationship between the different stream coordinate systems at any point in space-time), is sufficient for calculating which input stream fragments should be queried for a given fragment of output stream. If not a constant rate process, upper and lower bounds may be used to characterize the process rate, but a following stream merge will require serial stream reassembly.
An improved eduction model incorporates knowledge about the strictness
 of the tasks comprising the
dependency graph, allowing demands to leap-frog strict tasks. The
total computation latency and the demand processing overhead is
thereby reduced[Ski91]. The model of tasks defined here
doesn't really differentiate between non-strict and strict functions,
treating all tasks as strictly requiring the input data specified in
their parameter lists. If a stream, its stream access pattern, which
may represent a scatter or gather, indicates the data that is
required. Skipped stream values do not have to be defined. It is
assumed that not all values of a stream will ever be demanded.
of the tasks comprising the
dependency graph, allowing demands to leap-frog strict tasks. The
total computation latency and the demand processing overhead is
thereby reduced[Ski91]. The model of tasks defined here
doesn't really differentiate between non-strict and strict functions,
treating all tasks as strictly requiring the input data specified in
their parameter lists. If a stream, its stream access pattern, which
may represent a scatter or gather, indicates the data that is
required. Skipped stream values do not have to be defined. It is
assumed that not all values of a stream will ever be demanded.
The strictness constraint implies that the (possibly numerous) tasks associated with the production of a single demand of output data may theoretically all be identified and demanded at the initial demand. This is done is a distributed manner as there is no single dependency graph structure to trace. The demand (or query) process requires relaying the query message upwards through the stream and dependency linkings of the tasks.
If a particular fragment of a stream has been queried (demanded), the process producing that fragment should be executed as soon as possible. At the same time, since a fragment demanded may encompass many of the fragments actually used for scheduling and execution, a mechanism -- the BkOff message -- is provided for signaling that a particular stream fragment is no longer urgently needed.
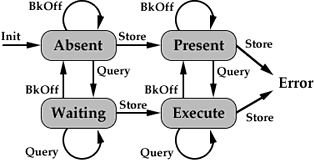
Stream Synchronization State Diagram