|
Stefan Marti, stefanm@media.mit.edu
MAS.967 Multilingual Computing
Final Project Proposal/Brainstorming:
Silent Speaking Recognizer
Problem
Basic idea: articulatory parameters as a substitute for spectrally based input parameters in speech recognizers. Or in other words: Developing a simple speech recognizer on the basis of real-time speech tract feature detection. The articulatory data of the oral movement is used to drive a speech recognizer.
Is it possible to make it very small and unobtrusive? Perhaps to place a wireless, very small sensor intra-orally? Or remote sensing with a reasonably small, external sensor?
Motivation
Wouldn't it be nice if you could talk in public on the cellphone without others listening to you and without bothering others?
Excerpt from my application to the MIT Media Lab, which in turn is a quote from my award-winning contribution to the 1994/95 international Leonardo da Vinci contest of IBM (it's a long time ago, so please pardon my language...):
|
"(...) But couldn't it be possible that such a simplification of telephony will eventually have catastrophic consequences for human society? Let's think of a world in which all humans are equipped with minute wrist or even ear-mounted "communication computers," enabling them to communicate handfree, anywhere and anytime. Isn't it possible that one would frequently bother the other people by soliloquizing unmotivatedly—this means, by making telephone calls without talking to the people currently around one? We seem to have a foretaste of this situation by people making cellular phone calls in every imaginable situation. Such an "acoustic-conversational pollution of the environment" could be fought by an invention that I have proposed: Silent Speaking. The principle is that speaking without the use of our vocal cords is made audible. When you say a word without using your vocal cords, the shape and volume of your mouth cavity changes respectively, as well as the position of your jaw and lips. If these quantities could be measured by miniaturized ultrasonic or ultraviolet sensors located, for example, on a tooth, a computer could possibly both learn to interpret them in relation to the corresponding sounds of speech and resynthesize them in realtime. The synthesized speech could be used to make phone calls. Such a speech recognizing and synthesizing technology, combined with extremely miniaturized terminal devices such as the above described handset within the ear, would enable us to telephone everywhere without bothering other people by our discontinuous babbling. Only the movements of our mouth would give a hint of our actual verbal telecommunication. Usually the original voice of the speaker himself is synthesized, but possibly also that of a completely different person! The generated voice would be reproduced in the speaker's own earphone too so that he can control her/his verbal utterances. This sort of voice entry, combined with an unrestricted and worldwi
de telecommunication by UMTS, together with a voice-operated computer in the ear, comes very close to a telepathic communication, technically realized!
The application of Silent Speaking is of course not limited to telephony. It could be useful too for ordinary personal computing, as an unobtrusive input device for any computer. As the voice has to be recognized before synthesizing, the conversion of spoken language to text is a by-product of Silent Speaking. This would be a very sophisticated and unobtrusive way of speech recognition, wouldn't it?
Of course there are many questions to be answered concerning the practical implications of Silent Speaking, e.g. Is our brain a real multitasking device at all?!? Is it possible to tele-communicate orally and to do another job at the same time? At what rate would the quality of another job done simultaneously decrease? (...)"
|
Approach
I have found a lot of relevant work, and even commercially available products of some kind:
|
Glove-Talk II matches gestures to vowels and consonants. Takes 100 hours to learn to speak. |
|
Alan Wrench: Multichannel/multispeaker articulatory database for continuous speech recognition research. Very good summary of the relevant research. He is focusing on measuring articulatory parameters to enhance the performance of ASR. |
|
Papcun, Zlokarnik did a lot of work, e.g., also the reverse process: from sound to articulary animation. |
|
Articulograph measures the 3D position of five sensors in the mouth with electromagnetic field. They used to have a helmet, now it is even bigger. |

|
|
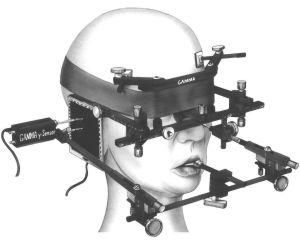
Axiograph measures the angle of the jaw. ONLY the angle of the yaw!! Looks to my like a torture instrument, extremely scary. |
|
|
X-ray Microbeam uses a narrow high-energy x-ray beam to track gold pellets attached to articulators while synchronously acquiring the physiological data. Not very portable: 15 tons. Gold pellets are secured by wires... |

|
Most information about these projects is from The Articulatory Database Registry
It is obvisous that these solutions are no option for my project. They are all far from practially usable, and most of them look very scary anyways...
So, back to the actual problem. Perhaps there are other options.
What features have to be detected?
Vertical distance of tongue to top of mouth (palatal?)
Horizontal distance of tongue from teeth
Distance between teeth
Width of lips
?
What kind of sensors are possible?
X-rays: too dangerous and too big
Electromagnetic: Articulograph. Like Polhemus, still too big
Contact sensors (Electropalatography EPG): e.g., Linguagraph, Palatometer
Ultrasonic?
Hybrid?
Visual, micro camera? Perhaps infrared camera?
An intelligent chewing-gum?
Expected results
Not a clue right now.
Conclusion, main problems right now
I feel uncomfortable if I have to wire up my (or other persons) mouth, or use a big machine that scans me. If I do this project, it has to be wireless and unobtrusive. Otherwise, I am not interested.
Class project last updated March 14th 2000.
Notes:
|