The perceptual principles that allow people to group visually similar objects into entities, or groups, have been referred to as the Gestalt Laws of perception. While the primary function of these "laws" is to help us perceive the world, they also enter into our communications. As a basis for simplifying discourse, people build on assumptions about each other's perception of the world. Two basic principles of perceptual grouping are proximity and similarity: objects that are close together are perceived to form groups; objects that are similar in shape, size or color are more likely to fall into groups than objects that differ along these dimensions. These principles allow people to refer to multiple objects as "those"--without any further verbal specification, often accompanied by indicative manual gesture or gaze.
The paper below describes an algorithm that simulates parts of this visual grouping at the object level. The system uses feature spaces and simple ranking methods to produce object groupings. The computational aspects of this system are described in detail and its uses for enhancing multi-modal interfaces are explained.
Thórisson, K. R. (1994). Simulated Perceptual Grouping: An Application to Human-Computer Interaction. Proceedings of the Sixteenth Annual Conference of the Cognitive Science Society, GA, Atlanta, Aug. 13-16, 876-881. [ps.Z].
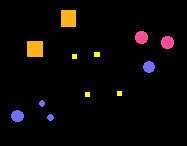
Each object in this image is coded for shape (discrete information), color (continuous information), size (discrete) and 2-D position (continuous). This information is processed automatically by the Gestalt algorithm to find "good" groups - groups that should match the groups a human would make. To come up with a decent grouping it processes the features together in a "holistic" manner, i.e. it takes all the features into account at once.
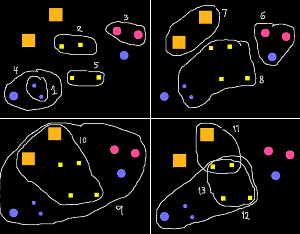
These are the 13 groups it came up with for the above input image. The groupings probably don't match your own in all aspect. Since the system doesn't take all the Gestalt principles of vision into consideration (it cannot simulate good continuation, symmetry or texture effects), its groupings cannot match a person's perfectly. (One may also wonder how different other peoples' grouping would be from one's own).
The system can deal with discrete and continuous data equally well, and can mix them, making it possible to input for example greyscale data (or brightness in the case of color), continuous color, and arbitrary categories of objects like apples, oranges, forks, knives, cars or beer, as long as their features are coded on a psychophysically calibrated scale.
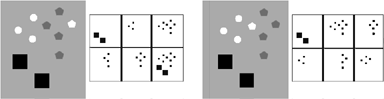
This image has objects varying along the features of (1) brightness (continuous, although in this particular example objects tend to fall into one of three clusters), (2) shape (discrete; circle, square, pentagon), (3) size (discrete; 2 sizes), and (4) position (continuous, 2-D). Input images have a grey background, output white. (The system outputs the most significant groups first; the order of the output in the above images is left to right for most significant to least significant, and top to bottom.) For demonstrative purposes, the graytone of two pentagons have been flipped in the two input images. Notice how the grouping mechanism does not make "rigid" interpretations but adjusts rather "smoothly" to this change.

[ Back to Thórisson's home page ]